V zapisu pišem o prispevku, ki sem ga letos predstavil v sekcijah uporabe naključnih matrik na 6. mednarodni konferenci ekonometrije in statistike EcoSta2023. Posvetim se tudi zanimivemu področju raziskovanja sferičnih naključnih polj, ki preči raziskovanja v verjetnosti, matematični statistiki in podatkovni znanosti. Posebej se dotaknem razmerja tega raziskovanja do novejših tem v matematični verjetnosti, kot sta Liouvillova kvantna gravitacija in naključna geometrija v splošnem.
Nadaljujte z branjemCategory Archives: Analiza podatkov
Cenilka razlike-v-razlikah za prostorskočasovne podatke
V prispevku pišem o cenilki, ki jo razvijam za posebno obliko metode razlike-v-razlikah za prostorsko časovne podatke. Cenilko sem letos predstavil v osrednjem programu ameriške konference vzročnega sklepanja ACIC 2023. Spodaj predstavim tudi njeno zanimivo uporabo v ekonometričnih analizah ekonomskih učinkov prireditev in dogodkov.
Razlika-v-razlikah oziroma difference-in-differences je statistični pristop k analizi opazovalnih podatkov v analizi vzročnosti, ki je prve uporabe našel v ekonometriji. Sodobnejše uporabe tega pristopa je spodbudilo delo ameriškega ekonomista Orleyja Ashenfelterja. Ashenfelter je znan tudi kot mentor oziroma raziskovalni svetovalec dveh nedavnih Nobelovih nagrajencev za ekonomijo, Davida Carda in Joshue D. Angrista. Zlasti Card je opravil pionirsko delo pri razvoju ekonometričnih metod analize vzročnosti v osemdesetih in devetdesetih letih prejšnjega stoletja, posebej znana je njegova študija skupaj s pokojnim Alanom B. Kruegerjem, ki je bila osnova za nedavno podelitev Nobelove nagrade.
Nadaljujte z branjemTenzorsko dopolnjevanje podatkov kot pristop k analizi podatkov občanske znanosti
V preteklih dveh letih sem se veliko ukvarjal z raziskovanjem podatkov občanske znanosti, kar je slovenski izraz za angleški pojem citizen science, ki ga je uvedel akad. prof. dr. Zdravko Mlinar v svojem prispevku v Časopisu za kritiko znanosti, domišljijo in novo antropologijo v letu 2021.
Izraz predstavlja koncept znanstvenoraziskovalnega dela, pri katerem so v raziskave vključeni neprofesionalni raziskovalci, kot so denimo dijaki in študentje, člani različnih društev, predstavniki posameznih družbenih skupin in drugi predstavniki zainteresirane javnosti, ki niso profesionalni raziskovalci. Občanski raziskovalci lahko delujejo v različnih fazah raziskave, kot npr. pri načrtovanju raziskave in pri formulaciji raziskovalnega problema, pri zbiranju in ustvarjanju raziskovalnih podatkov, pri analizi podatkov ter pri interpretaciji rezultatov (Vir: Občanska znanost).
Nadaljujte z branjemO modelih več indikatorjev in več vzrokov: zgodovina, delovanje in uporabnost
Modeli več indikatorjev in več vzrokov (ang. Multiple Indicators and Multiple Causes oziroma z okrajšavo MIMIC) se nahajajo na meji med ekonomsko statistiko in ekonometrijo. Čeprav so jih razvili pomembni avtorji iz zgodovine ekonometrije, kot sta Arnold Zellner in Dennis J. Aigner, ter o njih razpravljali ekonometriki kot Gary Chamberlain, pa se danes le še izjemoma uspejo prebiti na vodilne ekonometrične konference. V prispevku kratko predstavljam njihovo matematično strukturo in delovanje ter možnosti uporabe.
Nadaljujte z branjemDemonstracija uporabe metod tekstovnega rudarjenja: tipi socialne opore v spletni podporni skupnosti Neplodnost
Pomen socialne opore na ozdravitev in tudi smrtnost je bil že izpostavljen v številnih raziskavah (na primer Ali, Merlo, Rosvall, Lithman, and Lindström, 2006; McDade, Hawkley, and Cacioppo, 2006; Tomaka, Thompson, and Palacios, 2006). V grobem delimo socialno oporo na informacijsko in emocionalno. Prva vključuje posredovanje informacij osebi, ki potrebuje oziroma išče informacijo, emocionalna pa kot priznanje in ovrednotenje posameznikovih čustev ali nudenje utehe in spodbude (Sherbourne in Stewart, 1991). Ti dve vrsti socialne opore sta v največji meri prisotni tudi v spletnih podpornih skupnostih spoprijemanja z neplodnostjo. Ključni funkciji socialne opore sta blažilni učinek, ki ga ima na stresni odziv posameznika po prejemu informacije, ki povzroča stres. Lahko pa deluje zaviralno, to je prepreči stresni odziv še preden se ta pojavi. Pogovor z osebo, ki nudi socialno oporo, lahko namreč pomaga videti situacijo v drugi luči ali pa zaradi spodbude in empatije služi kot blažilec stresnega odziva. Poleg omenjenih tipov socialne opore, obstajata še dva, in sicer instrumentalna opora in druženje, ki pa sta v spletnih podpornih skupnostih prisotna v manjši meri.
Nadaljujte z branjemO učinkih samoizolacije zaradi COVID-19 v Sloveniji
Analize vzročnih učinkov ukrepov so metodološko področje, ki se nahaja med ekonometrijo in statistiko. Na tem blogu sem že večkrat pisal o področju vzročnega sklepanja v splošnem, pri ocenjevanju učinkov ukrepov pa se je razvilo veliko področje, ki so ga ekonometriki poimenovali metode ocenjevanja programov (angl. program evaluation). Med drugim je v povezavi z njim Nobelovo nagrado v letu 2000 prejel čikaški ekonomist in ekonometrik James Heckman, eden najbolj vplivnih med še živečimi ekonomisti. Področje je močno razvito na zahodu, še posebej v ZDA. V tem prispevku bom o njem spregovoril v povezavi s COVID-19.
Ko se je pandemija COVID-19 v začetku leta 2020 razširila po vsem svetu, je statistično in epidemiološko modeliranje njenega poteka postalo ena osrednjih točk znanstvenega raziskovanja. Novi koronavirus SARS-CoV-2 se je hitro razširil po vsem svetu in močno vplival na vse vidike našega življenja. Eden ključnih razlogov za njegovo hitro širjenje je visoko efektivno reprodukcijsko število R_t, o tem katerem sem pisal v prispevku, nastalem v začetku pandemije, Uvod v modeliranje in statistični vidiki COVID-19, poleg efektivnega pa poznamo tudi osnovno reprodukcijsko število R_0. Vrednost R_t predstavlja povprečno število ljudi, ki jih posameznik okuži v obdobju okužbe, pri čemer t predstavlja čas. Ko je R_t manjši od 1, se pojavnost novih primerov zmanjša, ko pa je R_t večji od 1, narašča, dokler epidemija ne doseže vrhunca; po tem se pojavnost novih primerov začne zmanjševati zaradi (vsaj začasne) čredne imunosti. Sliko gibanja števila primerov in umrlih v času pandemije v Sloveniji vidimo na spodnji sliki iz članka Manevskega in sodelavcev (2020), ki je eno od znanih slovenskih modeliranj COVID-19.
Nov pristop kombinatorne regresije

Vir: Towards Data Science
V prispevku predstavljam lasten pristop k regresijskemu modeliranju, poskusno predstavljen na lanskoletni konferenci AIMAC v Benetkah in pred predstavitvijo na veliki mednarodni konferenci računske in metodološke statistike CMStatistics, ki bo potekala preko spleta v decembru. Mislim, da predstavlja nekaj, kar danes zelo redko srečamo: povsem nov pristop in ne nadgradnjo obstoječega, nekaj torej, kar odpira velikanske možnosti bodočega raziskovanja, ki jih kratko predstavim spodaj.
Posvet o modeliranju in statističnih vidikih COVID-19
V torek, 21. aprila, smo v okviru 4. srečanja Mlade sekcije SdS prek spleta organizirali posvet na temo Modeliranje in statistični vidiki COVID-19 v Sloveniji, na katerem smo soočili pet strokovnjakov, moderirala pa sva ga dr. Andrej Srakar in jaz. Dogodek je gostil Inštitut za biostatistiko in medicinsko informatiko (IBMI), pri organizaciji in promociji dogodka pa je sodelovala tudi skupina COVID-19 Sledilnik.
Poskrbljeno je bilo tudi za prenos v živo in na spletu si lahko takoj po dogodku ogledali posnetek večjega pogovora do 21. ure (01:50:05). Celoten posnetek (02:35:55), ki vključuje tudi končno razpravo, pa si lahko ogledate na YouTube kanalu Mlade sekcije.
Predavanje Jožeta Sambta o anketi o porabi časa

Mlada sekcija Statističnega društva Slovenije je konec meseca marca pripravila svoje tretje srečanje. Po uvodnem srečanju, kjer smo skupaj s prof. dr. Katarino Košmelj govorili o statističnih eksperimentih in znamenitem Fisherjevem poskušanju čaja, ter drugem, kjer smo prisluhnili dr. Bojanu Nastavu, direktorju Statističnega urada RS (SURS) o uradni statistiki, je na tretjem predavanju spregovoril prof. dr. Jože Sambt iz Ekonomske fakultete Univerze v Ljubljani o anketah o porabi časa in medgeneracijskih transferjih neplačanega dela.
Uvod v modeliranje in statistične vidike COVID-19
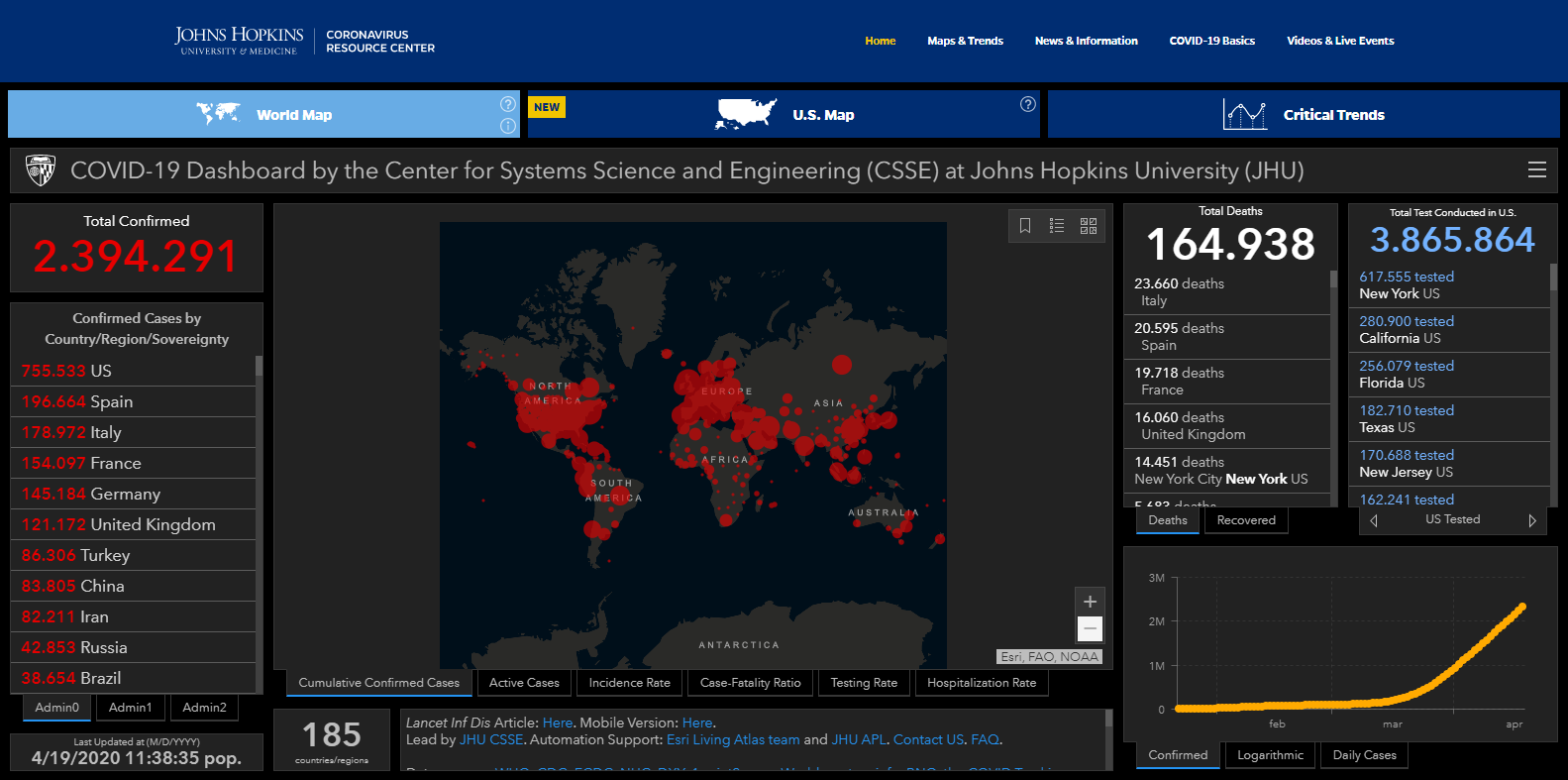
Vir: Johns Hopkins
V zapisu bom spregovoril o nekaterih ključnih modelih sedanje pandemije bolezni COVID-19, ki so nastali v Sloveniji. Pri tem se bom navezal na obstoječo literaturo v mednarodnih krogih, ki je v zadnjih dveh mesecih eksplodirala po verjetno prvi tovrstni študiji Kucharskega in kolegov v februarju 2020.
