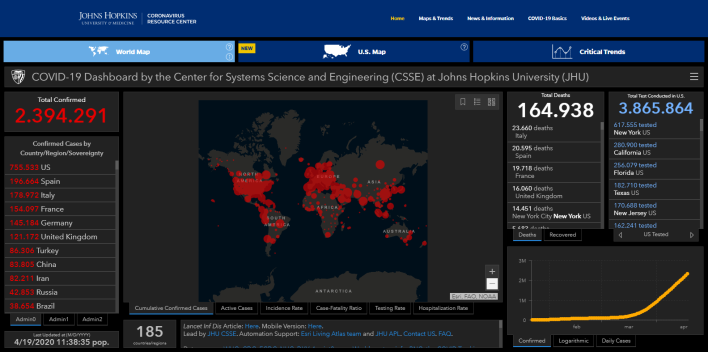
Vir: Johns Hopkins
V zapisu bom spregovoril o nekaterih ključnih modelih sedanje pandemije bolezni COVID-19, ki so nastali v Sloveniji. Pri tem se bom navezal na obstoječo literaturo v mednarodnih krogih, ki je v zadnjih dveh mesecih eksplodirala po verjetno prvi tovrstni študiji Kucharskega in kolegov v februarju 2020.
Kot je zapisal slovenski fizik Aleš Mohorič v prispevku za zadnjo številko Obzornika za matematiko in fiziko, v najbolj preprostem modelu začetek epidemije opišemo s številom novih bolnikov, ki jih okuži en oboleli (ki ga označimo z R0), in časom, v katerem se okužba prenese na naslednjo generacijo obolelih. Temeljno reprodukcijsko število R0 je merilo za to, kako nalezljiva je bolezen. V grobem pomeni povprečno število ljudi, ki jih okuži ena kužna oseba v času svoje kužnosti. To število določa, ali obolevnost narašča eksponentno (pri R0 > 1), ostaja konstantna, endemična (pri R0 = 1) ali pa upada (pri R0 < 1).
Epidemijo opišemo z različnimi modeli, ki lahko napovedo njen potek. Modeli temeljijo na določenih predpostavkah in parametrih. Med predpostavkami so, denimo, predpostavke o velikosti generacij in pričakovani življenjski dobi. Najpreprostejši model privzame, da je število oseb v vsaki generaciji enako. Druga predpostavka je, denimo, predpostavka o homogenem mešanju, kar pomeni, da so vse osebe v populaciji v medsebojnem stiku na podoben način (seveda so možna odstopanja, npr. podmnožice najstnikov, ki se bolj družijo med sabo, starostnikov, ali odročnejših skupin, pripadniki getov in podobno). Z izbranimi parametri lahko merimo učinkovitost ukrepov, kot sta npr. karantena ali množično cepljenje.
V grobem delimo tovrstne modele na verjetnostne (stohastične) in deterministične. V verjetnostnih modelih pripišemo posameznim izidom verjetnostne porazdelitve in iščemo ujemanje z dejanskim potekom, z variacijo nekaterih ključnih parametrov. V determinističnih modelih posameznike v populaciji razdelimo v podskupine, ki predstavljajo določeno fazo epidemije. Hitrost prehoda iz ene skupine v drugo izrazimo z ustrezno diferencialno enačbo. Velikost populacije v posamezni skupini je časovna spremenljivka in proces epidemije je determinističen, torej je sprememba podskupine podana z njeno preteklostjo in določena s parametri modela.
V preprostem determinističnem modelu SIR razdelimo populacijo na tri podskupine: ogroženi (susceptible, S), okuženi (infected, I) in odstranjeni (removed, R). Velikosti teh podskupin obravnavamo kot zvezne časovne spremenljivke. Okuženi lahko posredujejo bolezen ogroženim (zdravim), odstranjenim pa ne. V kategorijo odstranjenih sodijo ozdraveli, ki postanejo imuni, in bolni, ki umrejo. Posameznik v populaciji se lahko seli med podskupinami le v smeri od S proti I, od I proti R. Če privzamemo populacijo s stalnim številom N = S(t) + I(t) + R(t), opišemo prehode med podskupinami v najpreprostejšem modelu s tremi navadnimi diferencialnimi enačbami prvega reda:

kjer sta β in γ parametra, s katerima na zelo enostaven način določimo reprodukcijsko število R0 = β⁄γ. V začetni fazi bolezni se števila verjetno ne da določiti iz naraščanja števila obolelih v času, saj na začetku epidemije testiranja vedno zaostajajo in kažejo manjše število prizadetih kot jih je v resnici.
Model SIR je osnovni deterministični epidemiološki model in obstaja veliko dopolnjenih modelov, npr. model, ki upošteva rojstva in smrti. Ta model uporabljamo za opis epidemije, ki traja dolgo v primerjavi z življenjsko dobo ljudi v populaciji. V drugem modelu, modelu SIS, ozdraveli ne postanejo imuni, ampak se vrnejo v skupino ogroženih. Upoštevamo lahko tudi, da imunost traja le omejeno obdobje (model SIRS) ali pa, da ima bolezen latentno fazo, v kateri bolnik ni kužen (model SEIS ali SEIR). Tu črka E pomeni izpostavljenost (angl. exposed), torej okuženega, ki pa še ni kužen.
Poleg determinističnih pa se pri analizi epidemij uporabljajo tudi verjetnostni modeli. Kratek pregled nekaterih daje prispevek Linde J.S. Allen.
Na spodnji sliki je pregled nekaterih najbolj izpostavljenih študij pandemije bolezni COVID-19 do pričetka aprila, z navedbo metodologije, ki so jo uporabljale. Pri nekaterih gre za najbolj preprost model eksponentne rasti, pri številnih pa za zgoraj omenjene deterministične modele (večinoma tipa SEIR).
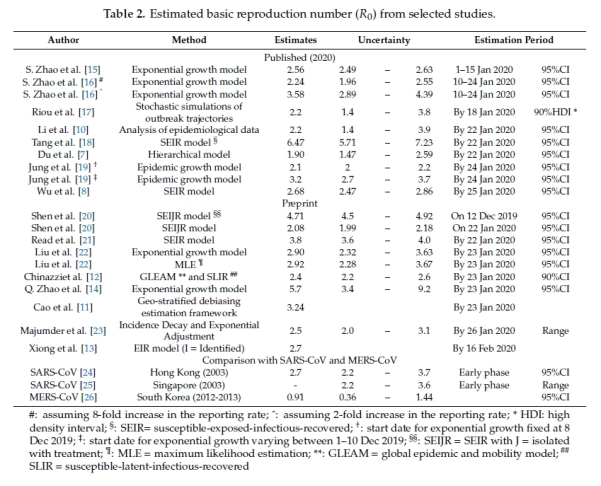
Pregled nekaterih zanimivejših, doslej objavljenih študij (Vir: Park idr., 2020)
Modeli, ki so glede pandemije bolezni COVID-19 nastali v Sloveniji, so obeh omenjenih vrst, deterministični in verjetnostni. V prispevku bom predstavil štiri modele, številni od njih pa so nastali v okviru projekta COVID-19 Sledilnik, katerega začetnik in koordinator je Luka Renko, koordinator modelskega dela pa dr. Aleks Jakulin, mednarodno priznani slovenski statistik, ki je več let predaval na newyorški univerzi Columbia.
Janez Žibert, izredni profesor na Zdravstveni fakulteti UL, je uporabil model SEIR, ki opisuje dinamiko prehajanja bolezni med dovzetnimi za bolezen (angl. Susceptible), izpostavljenimi bolezni (angl. Exposed), okuženimi (angl. Infectious) in ozdravljenimi (angl. Recovered). Njegov model, ki uporablja podatke, zbrane v okviru projekta COVID-19 Sledilnik je bil za potrebe boljšega modeliranja širjenja virusa v Sloveniji zaradi nezanesljivih podatkov o okuženih nadgrajen na modeliranje bolnišničnih obravnav, obravnav pacientov v intenzivni negi in smrti. Rezultati simulacij so dostopni na posebnem delu spletne strani Zdravstvene fakultete, kjer lahko najdete tudi povezavo do aplikacije za prilagajanje modela s spreminjanjem odprtih parametrov tej spletni strani, model pa lahko tudi poljubno prilagajamo s spreminjanjem odprtih parametrov na tej spletni strani.
Podatke pridobljene v okviru Sledilnika uporablja tudi model Žige Zaplotnika, podoktorskega raziskovalca na Fakulteti za matematiko in fiziko UL, vendar je njegov model verjetnostnega tipa na temelju metodologije analize socialnih omrežij. Njegova izboljšava determinističnih modelov je v bolj primernem vnaprejšnjem modeliranju učinka intervencijskih ukrepov na širjenje virusa, še posebej v zadnjih fazah epidemije, ko je okuženega prebivalstva le še malo in predpostavka o homogenem mešanju, omenjena zgoraj, postane neveljavna. Zaplotnik ustvari več socialnih omrežij iz več kot 2 milijona vozlišč, od katerih vsako predstavlja prebivalca Slovenije. V modelu primerja učinkovitost strategij ublažitve in zadrževanja virusa, kot sta središčna osamitev in sledenje stikov. Zanimiva ugotovitev je, da ostanejo ljudje, ki okužijo številne druge (tako imenovani super-razširjevalci), pomembni tudi v fazah upadanja pandemije.
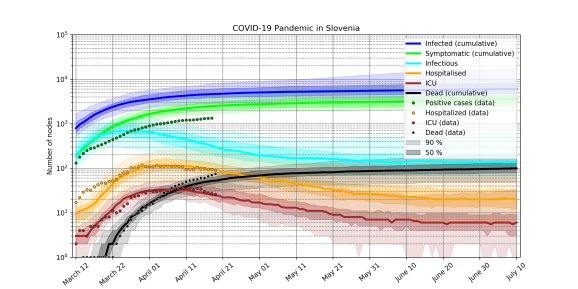
Vizualizacija iz študije Žige Zaplotnika (Vir: Zaplotnik idr., 2020)
Tretji model, ki ga omenjam, je nastal na oddelku za reaktorsko tehniko Inštituta Jožef Stefan in je delo Matjaža Leskovarja. Gre za točkovni model iz jedrske fizike, kjer se dinamika pandemije zreducira na obnašanje ene točke, ki predstavlja celo Slovenijo. Po svoji zasnovi je podoben modelom SIR. Model je prilagojen javno dostopnim podatkom in omogoča tudi modeliranje odzivov prebivalcev na sprejete ukrepe za preprečevanje širjenja. Predpostavljeni ključni parametri Leskovarjevega modela, ki so zanimivi za komentar vseh omenjenih modelov, so navedeni na spletni strani, kjer so v celoti dostopna tudi vsa druga gradiva modela.
Zadnji model, ki ga podrobneje omenjam, je verjetno edini, ki je nastal znotraj statističnih krogov. Gre za delo Damjana Manevskega, Maje Pohar Perme in Roka Blagusa z Inštituta za biostatistiko in medicinsko informatiko Medicinske fakultete Univerze v Ljubljani (povzetek lahko preberete tukaj). Model izhaja iz modela, uporabljenega v nedavni študiji raziskovalcev Imperial Collegea v Londonu. Raziskovalci Imperial Collegea uporabljajo model, utemeljen na Bayesovem pristopu za oceno verjetnih (angl. credible) intervalov za parametre vseh okuženih med prebivalstvom, verjetnosti prepoznanja posameznih primerov okužbe, ter dinamičnega reprodukcijskega števila Rt. Pri tem uporabljajo dve različni specifikaciji modela, eno, ki vključuje dvanajst evropskih držav, in drugo, v kateri sta izključeni Italija in Španija kot državi z najhitrejšo rastjo pandemije in najvišjima stopnjama smrtnosti med vključenimi državami.
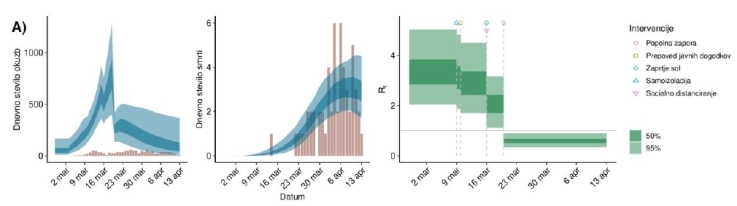
Vizualizacija iz študije Manevski, Pohar Perme in Blagus (vir: Manevski idr., 2020)
Omenil bi še probleme vzorčenja pri uporabi tovrstnih modelov, o čemer je na našem blogu že pisal tudi Andrej Viršček. Jasno je, da so podatki, zbrani iz testiranj, zbrani v namene ustreznega zdravljenja okuženega prebivalstva in niso bili podvrženi ustreznim statističnim načinom zbiranja podatkov, zato je sklepanje iz tovrstnih analiz na parametre v skupnem prebivalstvu pristrano. Sprašujem pa se, do kolikšne mere in ali bi morali obstoječi modeli to upoštevati pri svojih analizah. V epidemioloških študijah obstaja veliko literature na temo korekcij za pristranskosti izbora (angl. selection bias), dve pregledni gradivi sta dostopni tukaj in tukaj. Metode, ki se običajno svetujejo so denimo uporaba dodatnih spremenljivk v analizi (povezanih z razlogi za pristranost), metode nadomeščanja in uteževanja ter analiza občutljivosti.
Kolikor sem spremljal, je študija matematikov iz Univerze v Mariboru, ena redkih, ki se je sploh dotaknila problema pristranosti zaradi nenaključnega načina pridobivanja podatkov o pandemiji. Vendar se niti v tej študiji ne posvečajo velikosti morebitnih pristranosti. Prav od teh pa je odvisno marsikaj, tudi študije testiranja, kot se je sedaj loteva Slovenija. Omenjena študija mariborskih matematikov sicer uporablja generalizirane logistične modele rasti (posebej Richardsov model) in metode ponovnega vzorčenja za oceno treh scenarijev poteka pandemije v Sloveniji: optimističnega, realističnega in pesimističnega. Po realističnem scenariju se konec epidemije premakne med avgust 2020 in avgust 2021, po optimističnem med maj 2020 in avgust 2020, po pesimističnem pa med september 2020 in februar 2023. Model SEIR Nine Sivec Koren in Vasje Sivca je bil eden prvih javno predstavljenih modelov pandemije v Sloveniji. Lasten model je od začetka pandemije predstavljal matematik prof. dr. Dragan Marušič. Znotraj skupine COVID-19 Sledilnik je nastal tudi sestavljeni SIR model Matjaža Jerana. Zanimiv je tudi model SIR prof. dr. Gregorja Klančarja. Nedavno pa so svoj iteracijski model objavili tudi fizik prof. dr. Matjaž Perc in sodelavci.
Ob koncu še kratek razmislek o prihodnjem raziskovanju na tem področju. Zanimiv je pogled na zgornjo tabelo pregleda mednarodnih analiz, saj je v njej večidel najti SIR in SEIR modele. Glede na to bi bil večji razmah verjetnostnih modelov zelo dobrodošel, lahko pa bi se to nadgradilo tudi v modele z agenti. V prihodnjih tednih bo nujno v modele vključiti tudi ekonomske dejavnike, saj so tako rekoč vse države sprejemale pakete ukrepov odzivanja na krizo, ki imajo močan vpliv tudi na obnašanje ljudi, s tem pa na uporabljene parametre. S tega vidika je v zadnjih tednih že nastalo več modelov, kot je model SIR-Macro treh ameriških ekonomistov, ki v modele SIR vključuje spremenjeno obnašanje posameznikov zaradi sprejetih ekonomskih ukrepov. Še bolj pomembno pa bo odgovoriti na osnovno vprašanje: do katere mere so pristranosti podatkov zdravstvenih analiz vplivale na rezultate uporabljenih modelov in kako te pristranosti v bodoče odpravljati, kolikor je to mogoče. In še dodatek, revija Bayesian Analysis beleži kot najpogosteje brana v zadnjem tednu tudi dva prispevka na temo Bayesovega modeliranja epidemij, ki sta lahko zanimiva tudi za modeliranje pri nas – prvi in drugi.
O vseh teh vprašanjih bomo spregovorili na četrtem srečanju Mlade sekcije Statističnega društva Slovenije z naslednjimi govorci: dr. Aleks Jakulin, koordinator modelskega dela COVID-19 Sledilnik; dr. Žiga Zaplotnik, Fakulteta za matematiko in fiziko Univerze v Ljubljani; prof. dr. Janez Žibert, Zdravstvena fakulteta Univerze v Ljubljani; prof. dr. Maja Pohar Perme, Inštitut za biostatistiko in medicinsko informatiko Medicinske fakultete Univerze v Ljubljani. Pogovor bo potekal v torek, 21.4.2020 ob 19:00 prek spletne povezave Webex, vodila pa ga bova skupaj z dr. Ano Slavec.

Pingback: O učinkih samoizolacije zaradi COVID-19 v Sloveniji | Udomačena statistika