V prvem delu prispevka sta bila opisana način vzorčenja in vprašalnik Ankete o simptomih COVID-19, ki jo Univerza v Marylandu izvaja v sodelovanju s Facebookom. Prek aplikacijskega vmesnika za statistični program R sva pridobila podatke za Slovenijo in analizirala indikatorje, ki so uteženi in neglajeni.
Na voljo so podatki za obdobje od 3. maja do 10. novembra (objavljajo se za tri dni nazaj). Na dan je v anketi sodelovalo različno število ljudi, pri čemer so ga nekateri izpolnili v celoti, nekateri pa le delno. Če pogledamo vprašanje o simptomih, ki se pojavi takoj na začetku, je nanj odgovarjalo od 271 (3. maja) do 2227 oseb (20. maja); v povprečju 1136 oseb na dan. Povprečje je bilo najvišje v maju (1708 na dan) in je vsak mesec nekoliko upadlo – v novembru v anketi sodeluje povprečno 719 oseb na dan. Na nadaljnja vprašanja v vprašalniku pa je odgovarjalo manj oseb.
Podatki vključujejo spremenljivki Simptomi gripe in Simptomi COVID-19, ki sta sestavljeni na podlagi vprašanj o pojavnosti simptomov v zadnjih 24 urah. Simptomi gripe vključujejo vročino ter bodisi vneto grlo bodisi kašelj, medtem ko simptomi okužbe z virusom SARS-CoV-2 vključujejo vročino ter bodisi kašelj ali težave z dihanjem. Spodnja slika prikazuje deleža respondentov, ki so v zadnjih 24 urah imeli simptome ene ali druge bolezni. Sive lise predstavljajo 95 % interval zaupanja pri lokalnem uteženem glajenju (angl. locally weighted smoothing, LOESS).
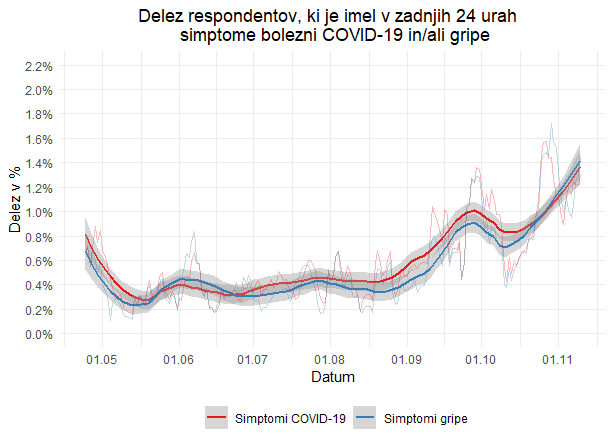
Čeprav se nakazuje, da je do sredine maja anketa zaznala nekoliko več tistih s simptomi COVID-19, nato do sredine junija več tistih s simptomi gripe, od julija do sredine oktobra spet več oseb s COVID-19 in od druge polovice oktobra naprej spet več gripe, gre za zelo majhne in neznačilne razlike, saj so si simptomi obeh bolezni zelo podobni. Deleža sta se sprva gibala v razponu od 0.25 do 0.5 %, konec oktobra pa sta oba presegla 1 %.
V anketi so respondente vprašali tudi po kraju, kjer so prespali prejšnjo noč, zato je delež respondentov s simptomi COVID-19 možno prikazati le po regijah, vendar le za štiri regije, kjer so zbrali dovolj odgovorov. To so Gorenjska, Osrednjeslovenska, Podravska in Savinjska regija, za katere deleže respondentov s simptomi COVID-19 agregirane na mesečni ravni prikazuje spodnja slika.

Delež respondentov s simptomi COVID-19 je bil sprva nizek in med regijami ni bilo veliko razlik, od avgusta naprej pa je začel delež naraščati, najbolj na Gorenjskem, kjer je delež v oktobru dosegel že 2 %, a je nato v novembru strmo upadel.
Oceno deleža oseb v Anketi o simptomih COVID-19 smo nato primerjali z deležem pozitivnih na testiranju za COVID-19 po podatkih projekta Sledilnik. Pri tem je treba poudariti, da gre seveda za dva povsem različna koncepta, ki sta tudi izračunana na dveh različnih populacijah. Pri deležu pozitivnih so populacija testirane osebe, njihovo število pa se je prav tako večalo. Pri deležu respondentov pa so ciljna populacija vsi prebivalci Slovenije – v praksi pa so zaradi omejitev vzorčnega okvira to le uporabniki Facebooka, ki se po starostni strukturi in drugih značilnostih razlikujejo od celotne populacije, vendar napako do neke mere popravijo z uteževanjem.
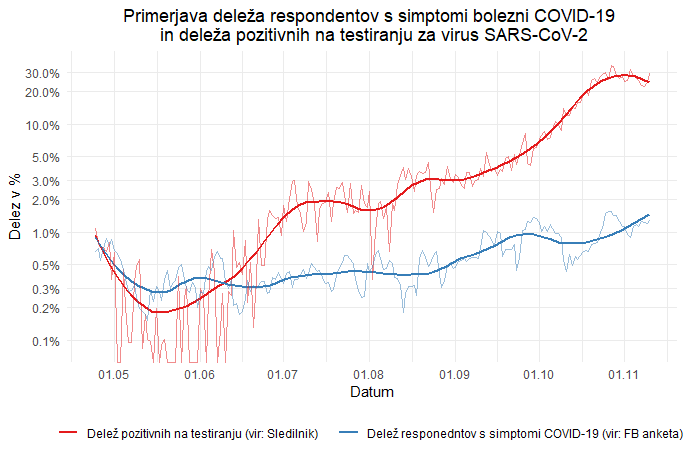
Zanimivo je, da je bil delež respondentov s simptomi ves čas vrtel od 0.3 do 1 %, medtem ko je bil delež pozitivnih na testiranju zelo nizek, nekaj časa celo pod deležem respondentov v populaciji s simptomi, v drugi polovici junija pa je začel naraščati in stabilno rasel ves čas in v novembru dosegel 30 %.
Respondente so v anketi o simptomih vprašali tudi, ali so imeli v zadnjih 24 urah neposreden stik z osebo izven gospodinjstva. Kot prikazuje spodnja slika, je bilo konec aprila takih le četrtina oseb, nato je delež narašal in sredi maja presegel 50%, sredi junija pa dosegel vrh okrog 60 %. Nato je nekoliko padel, vendar se je vse do konca septembra vrtel okrog 50 % in in šele v oktobru začel padati. Po uvedbi policijske ure 20. oktobra se je ustalil na okrog 30 %.
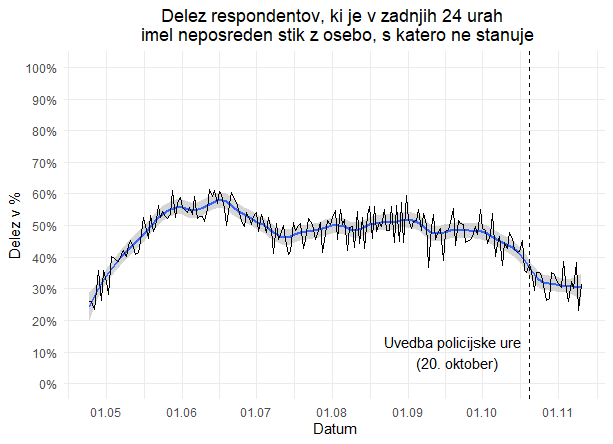
Zanimivo bi bilo preveriti, ali so razlike v deležu stikov posamezniki s simptomi in tistimi brez, saj so prvi bolj verjetno okuženi z virusom, zato njihovi stiki predstavljajo večje tveganje za širjenje bolezni. Vendar na podlagi agregiranih podatkov tega žal ni možno preveriti – za podrobnejšo analize bi morali pridobiti dezagregirane podatke.
Tiste, ki so imeli v zadnjih 24 urah neposreden stik z osebo izven gospodinjstva, so nato, med drugim, vprašali, ali so v zadnjih sedmih dneh na javnih površinah nosili masko. Kot prikazuje spodnja slika, je bilo od aprila do konca maja pritrdilnih odgovorov okrog 75 %, nato pa je delež v juniju hitro padel in v drugi polovici junija je bilo takih manj kot polovica. Nato je število začelo naraščati in že v juliju je bil delež spet 75 %, od uvedbe obveznega nošenja mask na prostem sredi oktobra pa je delež dosegel skoraj 80 %. Tako, kot pri deležu stikov, tudi pri nošenju mask razlike v obnašanju med simptomatskimi in asimptomatskimi posamezniki ni možno preveriti.

V anketi je bilo tudi vprašanje, ali so zaskrbljeni glede finančnih sredstev gospodinjstva za prihodnji mesec. Delež tistih, ki so zelo ali delno zaskrbljeni, se je vseskozi vrtel okrog 30 % brez pomembnejših razlike med meseci. To se ujema tudi z Valicononovo raziskavo Nova normalnost, ki je v zadnjem tednu aprila izmerila, da 31 % oseb pričakuje poslabšanje finančne situacije. Zanimivo bi bilo preveriti razlike po več demografskih spremenljivkah, ki pa jih v agregiranih podatkih ni na voljo.

Agregirani podatki pridobljeni prek aplikacijskega vmesnika so žal omejeni le na zgoraj prikazane spremenljivke in ne omogočajo analize na nivoju enote. Za dostop do podatkov za celotni nabor spremenljivk in bolj poglobljene analize je treba pripraviti prošnjo za dostop do dezagregiranih podatkov, ki pa se odobri le v raziskovalne namene.
Če bi pridobili dezagregirane podatke bi tako lahko preverili, ali so v upoštevanju ukrepov distanciranja in nošenja mask razlike med simptomatskimi in nesimptomatskimi posamezniki ter tudi vpliv kontrolnih spremenljivk. Prav tako bi bilo zanimivo raziskati povezavo med zaskrbljenostjo zaradi finančnih sredstev in spoštovanjem ukrepov.
Tako pri analizi na podlagi agregiranih kot dezagregiranih podatkov pa se moramo zavedati tudi njihovih omejitev. Čeprav gre za kakovostne podatke, kjer je z uporabo naprednih statističnih metod poskrbljeno za ustrezno utežitev vzorca, ki omogoča sklepanje na populacijo, še vedno ne gre zanemariti pristranskosti zaradi nepokritja, neodgovorov in merskih napak, ki jih ni možno kontrolirati na podlagi kontrolnih podatkov, ki jih o svojih uporabnikih zbira Facebook. Zlasti je to težava v zadnjem mesecu, ko je število odgovorov na dan pri nekaterih vprašanjih upadlo pod 200.

Pingback: Anketa o simptomih COVID-19, 1. del: Opis vzorčenja in vprašalnika | Udomačena statistika
Pingback: Anketa o simptomih COVID-19, 3. del: Primerjava s sosednjimi državami | Udomačena statistika