
Slika 1: John Aitchison (Vir: Wikipedia)
V drugem prispevku o simbolni analizi podatkov bomo govorili o sorodni metodi – analizi mešanic (angl. compositional data analysis, velikokrat boste srečali tudi kratico CoDa). Metodo analize mešanic je v statistiki utemeljil in razvil nedavno preminuli škotski statistik John Aitchison, ki je za delo na tem področju leta 1988 prejel tudi srebrno Guyjevo medaljo britanskega Kraljevega statističnega društva, ki velja za eno najprestižnejših statističnih priznanj na svetu.
Analiza mešanic se ukvarja z odstotki oziroma, pravilneje rečeno, z deli izbrane celote, o katerih imamo le relativne informacije, ki nam povedo le razmerje do drugih podobnih informacij. Govorimo o spremenljivkah, pri katerih so vrednosti podane kot verjetnosti, deleži, razmerja itd. Pri tem imamo naenkrat opraviti z vektorji, sestavljenimi iz vrednosti, matematični – geometrijski prostor preučevanja pa se spremeni iz običajnega kartezijanskega v simpleks, torej v n-razsežno analogijo trikotnika. V zvezi s tem je o problemu navidezne korelacije konec 19. stoletja prvič pisal Karl Pearson. Na nekoliko drugačen način pa je navidezno korelacijo v povezavi s časovnimi vrstami obravnaval Nobelov nagrajenec Clive W.J. Granger).
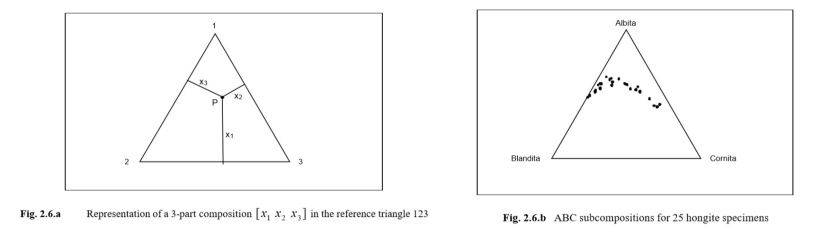
Slika 2: Prikaz tridimenzionalnega simpleksa (v tem primeru trikotnika) za podatke analize mešanic. (Vir: leq.upfr.br, str. 48 in 49).
Operacije, s katerimi statistično preučujemo razmerja med takšnimi spremenljivkami, so precej drugačne od tistih, ki jih poznamo iz klasične statistike. Poznamo dve glavni operaciji: perturbacijo ali kompozicijsko seštevanje in potenčenje oziroma kompozicijsko množenje (angl. power operation). Novi načini računanja seveda zahtevajo tudi poseben pristop k analizi. Ni več dovolj upoštevati običajna razmerja, pač pa analiza zahteva določene prilagoditve, transformacije, najpogosteje povezane z logaritmi. Gre za središčne logaritemske razmernostne koeficiente (angl. centred log-ratio coefficients – clr), v izpeljavi Juana Joséja Egozcueja in sodelavcev pa se uporabljajo tudi izometrični logaritemski razmernostni koeficienti – ilr.
Zaradi zgoraj navedenega se seveda sremenijo vsi izračuni: za osnovne opisne statistike, multivariatne metode, tudi regresijo. Tudi preverjanje hipotez ima povsem spremenjeno, večstopenjsko shemo. Obstajajo tudi posebne metode, ki naslavljajo za ta pristop običajen problem ničelnih vrednosti (načeloma morajo biti v takšni analizi vse vrednosti razmerij pozitivne). Pomemben članek o tem so pripravili prof. Fry in sodelavci.
Problem predstavlja tudi določanje parametrov pri tem pristopu: kakšne porazdelitvene predpostavke uporabiti pri analizi, ali gre za lognormalne, Dirichletove, sestavljene multinominalne, multivariatne beta, ali katere druge porazdelitve? Nekatera izhodišča analize mešanic namreč izhajajo iz predpostavke, da je porazdelitev tržnih deležev pri podjetjih običajno precej bliže generaliziralnim normalnim, t.i. Subottinovim porazdelitvam, kot pa bolj običajnim normalnim (Gaussovim) ali Laplaceovim porazdelitvam.
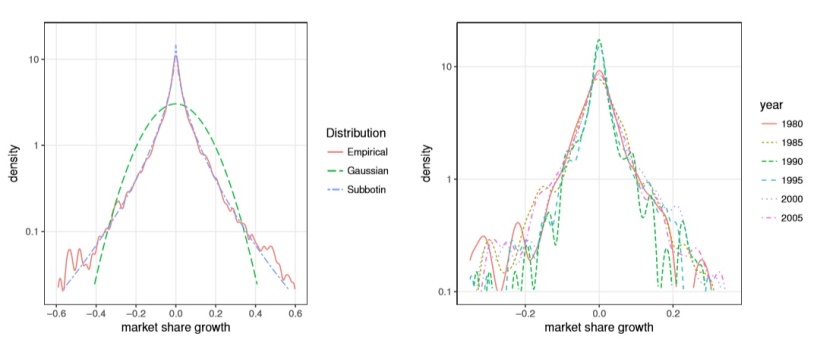
Slika 3: Empirično ustrezanje različnih statističnih porazdelitev podatkom analize mešanic (Vir: rieti.go.jp, str. 13).
Analiza mešanic je tudi ena izmed metod za statistično in ekonometrično preučevanje tržnih deležev, t.i. market share analysis. Gre za modele, kot so predvsem “atrakcijski” modeli (MCI/MKI – Multiplicative Competitive Interaction Model oz. model multiplikativnih konkurenčnih interakcij; multinominalni modeli na tem področju; polni faktorski model oz. Full-Factorial Model, itd.) in še mnogi drugi. Kolikor vemo, se pri nas v statistični in ekonometrični analizi ti modeli le redko uporabljajo, čeprav odpirajo veliko možnosti za zanimive analize.
V prispevku sem v grobem opisal dve sodobni statistični metodi, ki odpirata velike možnosti nadaljnjega raziskovanja. Čeprav gre pri prvi, simbolni analizi podatkov načeloma za metodo, ki je nastala iz analize t.i. masivnih podatkov (in se jo tudi v splošnem uvršča v t.i. rudarjenje podatkov oz. data mining), pa menim, da je njeno bistvo povsem drugje: gre, kot smo prikazali, predvsem za povsem nov pogled na statistiko. Delo z vektorji in relativnimi merami pri metodi analize mešanic pa odpira lep in drugačen matematičen svet[1]. Omenil sem tudi možnosti analize tržnih deležev, ki so zanimivi za bodoče delo v statistiki, še bolj pa v ekonometriji – dveh področjih, ki sta tesno povezani in se prepletata, čeprav sta v veliki meri tudi različni. Obe odpirata še ogromno novih in vsaj v praksi še neraziskanih področij, ki se jih bom poskušal vsaj bežno dotakniti v katerem od naslednjih prispevkov.
[1] Za osnovni vpogled v predstavljeni pristop analize mešanic predlagam odličen in dobro berljiv, prosto dostopen Aitchisonov učbenik A Concise Guide to Compositional Data Analysis. Posamezni modeli pa so zelo dobro opisani v odlični monografiji Leeja G. Cooperja in Masaeja Nakanishija.

Pingback: Predavanje Jožeta Sambta o anketi o porabi časa | Udomačena statistika
Pingback: Rajski teden za matematično usmerjene – o letošnjem prvem One World simpoziju | Udomačena statistika