Marca, sem na skupščini Statističnega društva Slovenije predstavil enega najuspešnejših razvojnih projektov Statističnega urada Republike Slovenije (SURS), v katerem so uporabljeni procesi strojnega učenja. Vzpostavljen je bil zaradi potrebe po drugačnem pristopu zbiranja cen in lastnosti računalniških komponent za izračun inflacije.
Takih razvojnih projektov je na SURS-u sicer več, vendar je ta prvi, ki je prešel v redno produkcijo, in pravšnji za razumljivo razlago ustrezne obdelave podatkov z uporabo strojnega učenja. V predstavitvi sem zaobjel bistvo izzivov in novih spoznanj, s katerimi smo se morali spopasti pri razvoju procesov in so značilni pri delu s strojnim učenjem.
Projekt je nadaljevanje prejšnjih raziskovanj uporabe spletnih podatkov in je značilen primer uvrščanja besedilnih podatkov v predhodno določene skupine. V letu 2018 smo na SURS-u tako začeli s prenovo postopka za izračun inflacije na področju računalniške opreme, v katerem je bila glavna sprememba uporaba spletnih podatkov. Posledica tega je tudi nov način računanja končnih indeksov.
V preteklosti so se podatki zbirali z zelo majhnimi vzorci reprezentativnih izdelkov iz vsake primerne skupine. Vendar pa se lastnosti računalniške opreme hitro spreminjajo in na trgu se nenehno pojavljajo vedno boljši izdelki, zaradi česar so se morale ob menjavah izdelkov v košarici izvajati pogoste kvalitativne prilagoditve. Take prilagoditve so časovno in delovno zahtevne. Ker so vsi potrebni podatki javno dostopni na straneh spletnih trgovin z računalniško opremo in ker avtomatizirano podatkovno strganje celotne ponudbe zahteva manj časa in dela, smo začeli razmišljati o spremembi procesov zbiranja. Naša prva naloga pri prenovi je bila definicija novih procesov.
Podatkovno strganje omogoča zajem zelo velikega števila raznolikih in včasih tudi pomanjkljivih podatkov, z ustreznimi metodami standardizacije in imputacij pa lahko ustvarimo bogato bazo primerljivih informacij. Večje število izdelkov v izračunu pomeni tudi izboljšanje kakovosti indeksov. Avtomatizacija prav tako razbremeni anketarje, vendar poveča število izdelkov, ki jih je potrebno ustrezno razvrstiti v skupine. Zaradi velike količine podatkov ročna izvedba tega postane nemogoča, zato se mora uporabiti pristop klasifikacije z metodami strojnega učenja. S spremembo podatkov se mora spremeniti tudi metodologija in način obdelave podatkov, oboje pa je potrebno preveriti z vidika kakovosti, ki jo mora SURS zagotavljati pri svojih proizvodih.
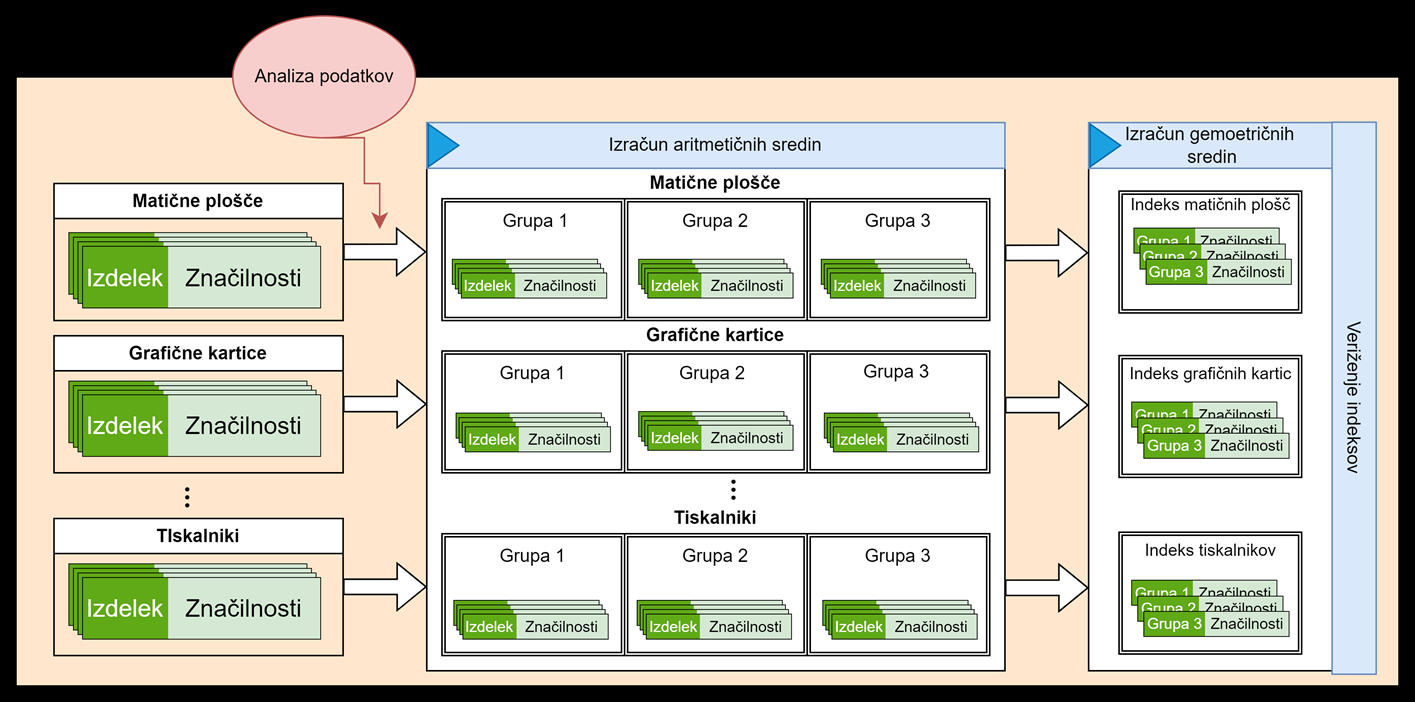
Prvi korak v projektu je bila analiza podatkov, v kateri smo ugotavljali, kakšne so sploh zmožnosti in posebnosti strganja teh podatkov, ter izbrali ustrezne lastnosti za vsako skupino. Tako smo določili pristop k strganju podatkov spletnih trgovin in njegovo implementacijo. Strganje je enostavno in omogoča pogostejše zbiranje podatkov, kot smo ga navajeni do sedaj. V produkciji se izvaja enkrat tedensko za 22 največjih spletnih trgovin, z njim pa zberemo sto tisoč izdelkov vsak prvi teden v mesecu, nato pa še okoli štiri tisoč novih izdelkov v drugem tednu meseca. Zbirajo se podatki o trenutnih in rednih cenah, dobavljivosti, lastnostih, znamki, besedilni opisi in tako dalje.
Strganje je osredotočeno na 17 skupin izdelkov, ki vključujejo računalniške komponente, pa tudi zunanjo opremo (miške, tipkovnice, ekrani, tiskalniki, ipd.). Strojno učenje se nato uporablja za razvrščanje izdelkov v eno od teh skupin. Zaradi narave spletnih trgovin se izvaja še sekundarno strganje, s katerim se izločijo neveljavni izdelki, bodisi zaradi neveljavnih lastnosti (npr. termični tiskalniki) bodisi zaradi neveljavnosti izdelka (npr. torbe za prenosnike), ki se včasih pojavljajo v kombinaciji z relevantnimi izdelki. Pri predstavljanju sem poudaril, kako pomembna je bila priprava učnih množic in koliko dela je bilo vloženega v to, da so bile pravilno sestavljene.
Razvrščanju sledita še analiza in obdelava podatkov o izdelkih. Izlušči se podatke iz besedil, kakršnekoli enote v lastnostih izdelkov so poenotene, odstrani se primere z ekstremnimi vrednostmi in napačnimi oz. nelogičnimi vrednostmi. Mesečno se spremlja pojavljanje novih lastnosti, ki se morajo pri nadaljnjem obdelovanju upoštevati kot pomembne.
Prikaz pristopa do izračuna indeksov (vir: Črt Grahonja)
Nato se izvedeta gručenje in izračun indeksov. Manjkajoče vrednosti se imputira z metodo najbližjega soseda, nato pa se ustvari homogene enote po sistemu Banff z uporabo razvrščanja v skupine po metodi K‑means. Vsaka od teh homogenih skupin prevzame vlogo reprezentativnega izdelka. Najprej se izračuna uteženo aritmetično sredino cen homogenih skupin. Vsakemu izdelku se določi utež, ki predstavlja delež prodaje trgovca za izbran segment. Iz tega se ustvari mesečni indeks cen za vsako homogeno skupino. Nato se z uteženo geometrično sredino izračuna mesečni indeks, v katerem so uteži število enot v vsaki homogeni skupini. Indekse se na koncu še veriži. Tako izračunani indeksi imajo napram prejšnjemu postopku prednost, saj boljše odražajo stanje na trgu, za katerega je značilna hitra izguba vrednosti.
Predstavitev sem zaključil s hitrim povzetkom ostalih projektov, ki so večinoma še v razvojnih ali testnih fazah. Ob primerjavi sem lahko ustrezno razložil težave zaradi nepravilnih priprav učnih množic in kako pomemben je vnaprejšnji premislek, kako se lotiti celotnega procesa. Izpostavil sem tudi naše poskuse na nekaterih najsodobnejših metodah, kot sta optično prepoznavanje slik in uporaba velikih jezikovnih modelov (LLM).
S predstavitvijo sem Statističnemu društvu želel pokazati, koliko dela in truda vlagamo na SURS-u za to, da smo na področju novih statističnih in podatkovnih postopkov v koraku z drugimi institucijami. Društvo je izkazalo navdušenje nad našimi prizadevanji in precejšnje zanimanje v obliki zanimivih vprašanj, zato menim, da sem svojo namero izpolnil.
Pripravil: Črt Grahonja, magister finančne matematike in podsekretar na Statističnem uradu RS
