
Edwin Diday, ki je skupaj z Lynne Billard začetnik simbolne analize podatkov (Vir: modulad.fr)
V prispevku, ki je moj prvi na Udomačeni statistiki, želim kratko predstaviti dve metodi, s katerima sem se srečal v prvem letniku doktorskega študija statistike in se “zaljubil” vanju. Prvo, analizo simbolnih podatkov (angl. symbolic data analysis) sem spoznal pri predavanjih predmeta Sodobni statistični pristopi, kjer nam je o njej predavala doc. dr. Simona Korenjak Černe z Ekonomske fakultete. Drugo, analizo mešanic (angl. compositional data analysis) pa, zanimivo, bolj po naključju prek običajnega dnevnega statističnega in ekonometričnega brskanja po internetu. Najprej sem odkril, da je zanjo velik specialist tudi sedanji predsednik Statističnega društva Slovenije, prof. dr. Matevž Bren. Nato pa še večje presenečenje: da je na tem področju mednarodna referenca (kolikor mi je to znano) prof. dr. Tim Fry, ekonometrik in dekan Šole za ekonomijo, finance in marketing na RMIT v Melbournu (eni najboljših avstralskih univerz) ter odgovorni za organizacijo konference svetovnega združenja kulturnih ekonomistov ACEI drugo leto v Melbournu, pri kateri sem tudi sam v programskem znanstvenem odboru (kot nekdo, ki že več kot desetletje zelo aktivno deluje tudi na področju kulturne ekonomike). S prof. Fryjem pripravljava članek o uporabi metode analize mešanic pri analizi mednarodne menjave s kulturnimi dobrinami za nekatere statistične probleme, ki niso povsem običajno rešljivi z najbolj enostavnimi pristopi analize mešanic.
Namen tega prispevka seveda ni predstaviti podrobnosti obeh metod, pač pa prikazati njune osnovne značilnosti. Povedal bom tudi, zakaj se mi zdita pomembni za delo v sodobni statistiki. Zato bom izpustil mnoge podrobnosti, ki jih lahko najdete v literaturi s teh področij.
Pričnimo s simbolno analizo podatkov. Ko smo s kolegi na Ekonomski fakulteti in Inštitutu za ekonomska raziskovanja, pripravili neformalne ekonometrične seminarje, so bili mnogi navdušeni nad možnostmi, ki sta jih na prvih dveh seminarjih odlično prikazala izr. prof. dr. Anže Burger (o analizi kavzalnosti v ekonometriji) in doc. dr. Martin Žnidaršič (o strojnem učenju in uporabi v ekonomiji). Analiza kavzalnosti je “klasična”, ko govorimo o ekonometriji, čeprav še vedno odpira velikanske možnosti novih raziskovanj. Posebej druga, strojno učenje, pa zaseda trenutno veliko prostora v razpravah o statistiki in se vedno pogosteje pojavlja tudi na področju ekonomije. Kolegom, s katerimi pripravljamo seminarje (Gibanje za ekonomsko pluralnost, GEP), sem v kratki napovedi seminarja povedal, da je simbolna analiza podatkov zame še bistveno bolj vznemirljivo področje od predhodnih dveh.
Zakaj? Ker gre pri simbolni analizi podatkov, katere začetnika sta bila predvsem matematika Edwin Diday in Lynne Billard[1], za povsem nov konceptualen pogled na statistiko. V njem spremenljivke niso več le številke, pač pa so dejansko lahko kar koli. Povedano v jeziku matematike je “točka” v analizi simbolnih podatkov hiperkocka v p-dimenzionalnem prostoru ali pa kartezijski produkt porazdelitev. Na tak način vrednosti v simbolnih podatkih niso več omejene na številke z le eno numerično vrednostjo. V današnjem stanju simbolne analize podatkov ločimo naslednje tipe takšnih spremenljivk: intervalne, ko je spremenljivka dejansko interval vrednosti, omejen spodaj in zgoraj (denimo krvni tlak, telesna teža); večvrednostne/kategorialne, ki so sestavljene iz vrednosti po kategorijah spremenljivke (denimo vrsta bolezni, vrsta avtomobila); ter modalne, ki so spremenljivke z več stanji (angl. multistate), ki imajo vsaka svojo frekvenco, verjetnost ali utež (denimo kumulativna porazdelitev neke spremenljivke po izbranih kvantilih).
Tak tip podatkov seveda zahteva povsem drugačen pristop k analizi v smislu matematičnih in statističnih formulacij. Že izračun osnovnih opisnih uni- in bivariatnih statistik, kot so povprečje, standardni odklon, korelacija in kovarianca, je povsem drugačen (Več o tem v omenjenem temeljnem članku tega področja). Zaenkrat bi lahko dejali, da je področje še precej nerazvito, vsaj v luči ogromno možnosti, ki jih verjetno ponuja.
Naj povedano ilustriram s primerom iz omenjenega članka Billardove in Didayja. Denimo, da nas zanimajo vsi živeči v Bostonu, hkrati pa imamo podatke o številu otrok, ki jih ima vsak posameznik v vzorcu (z vrednostmi 0, 1, 2 ter 3 ali več otrok). Iz tega izhajajoča simbolna (modalna) spremenljivka je število otrok za živeče v Bostonu, ki je sestavljena iz štirih vrednosti, ki opisujejo relativne frekvence za vse tiste z nič, enim, dvema ter tremi ali več otroki. Pri nadaljnji analizi ne uporabljamo več osnovne “točkovne” spremenljivke števila otrok, pač pa novo, simbolno spremenljivko, ki je sestavljena iz štirih vrednosti in je ne moremo več opisati v preprostem kartezijanskem prostoru (glej sliko spodaj).
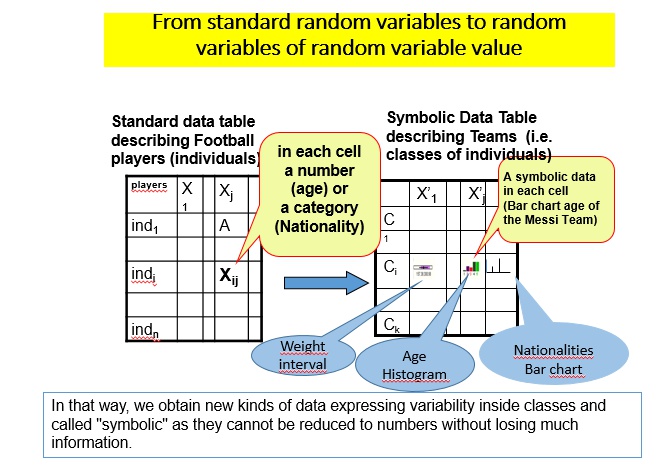
Od standardnih podatkovnih tabel do podatkovnih tabel simbolnih podatkov (Vir: Diday 2014, slide 7/62)
Kratko omenimo nekatere znane uporabe in razvite metode na področju. Cazes idr. (1997) ter Chouakria (1998) so razvili metodo glavnih komponent za simbolne podatke (intervalne spremenljivke). Faktorsko analizo za intervalne spremenljivke so razvili Cheira, Brito in Duarte Silva (2015). Metodo glavnih komponent za trismerne podatke (angl. three-way data) je oblikoval Ichino (2011). Številne metode so bile razvite za simbolno razvrščanje v skupine, denimo razdruževalne metode, razvite v Michalski, Diday in Stepp (1981) ter Michalski in Stepp (1983) ter aglomerativne, razvite denimo v Diday (1987) in Brito (1994, 1995). Med regresijskimi modeli naj omenim ločitev na modele za intervalne podatke (denimo Billard in Diday, 2000; 2002; 2006; Lima Neto in De Carvalho, 2008; 2010; ter Ahn idr., 2012) ter histogramske/modalne spremenljivke (tu obstajajo trije osrednji modeli, razviti v prispevkih Billard in Diday, 2006; Dias in Brito, 2015; ter Irpino in Verde, 2015).
Eden izmed pomembnejših dogodkov na področju je vsakoletna delavnica, ki je v letošnjem letu potekala tudi v Ljubljani, kjer so bile prisotne tako rekoč vse vodilne osebe na področju, vključno s prof. dr. Didayjem in prof. dr. Billardovo.
Treba je povedati, da smo na področju zelo aktivni tudi slovenski raziskovalci: v prvi meri skupina prof. dr. Vladimirja Batagelja, v kateri zelo aktivno delujeta predvsem že omenjena doc. dr. Simona Korenjak Černe in dr. Nataša Kejžar. Vsi navedeni so močno povezani tudi s študijem statistike pri nas, prva dva kot predavatelja, Nataša pa kot ena prvih doktorandk statistike na študiju v Sloveniji. Intervju z njo ste v preteklih letih lahko prebrali tudi na tem blogu.
[1] Billard, L. in Diday, E. (2003). From the Statistics of Data to the Statistics of Knowledge: Symbolic Data Analysis. JASA. Journal of the American Statistical Association. June, Vol. 98, N° 462; in Billard, L. in Diday, E. (2006). Symbolic Data Analysis: Conceptual Statistics and Data Mining. Hoboken, New Jersey: John Wiley and Sons.
